
從現在起開始陸陸續續寫一些吧,大概的計劃是將Pattern Recognition and Machine Learning的學習體會寫一個專題,然后繼續deep learning方面的論文學習,當然也有編程方面的東西,希望能夠好好堅持。下面是近期看的層級實時網絡(HTM)的總結,HTM也是deep model的一種。這部分內容基本是本人脫離論文進行的回顧,如果有錯誤,各位看官還望原諒及指正,謝謝!
PART ONE: OUTLINE
皮質學習算法
Cortical Learning Algorithm
摘要
Abstract
緒論
Introduction
1、皮質學習算法的歷史沿革
2、皮質學習算法的主要思想
3、報告的主要框架
George博士論文中的層級實時記憶算法
HTM: version I in George’s PhD thesis
1、整體框架
2、識別
3、學習
4、總結
Numenta白皮書中的層級實時記憶算法
HTM: version II in Numenta’s White Paper
1、整體框架
2、Sparse Distributed Representation
3、Spatial Pooler
4、Temporal Pooler
5、與Version I的內在聯系與主要區別
6、總結
層級實時記憶算法的實現
The implementation of HTM
1、Encoder
2、Spatial Pooler
3、Temporal Pooler
4、CLA Classifer
5、總結
總結與展望
參考文獻
PART TWO: REPORT
皮質學習算法
Cortical Learning Algorithm
摘要
Abstract
皮質學習算法是一種對新大腦皮質層結構與功能運作進行人工模擬的算法。本篇報告主要闡述了皮質學習算法的發展概況,核心算法(Hierarchical Temporal Memory: HTM)以及算法中的關鍵技術。通過對HTM算法各設計細節的分析,對HTM算法的演變進行學習和思考,加強對算法核心內容,如空間模式與時間模式的提取,稀疏離散表征等的理解。同時,對開源代碼及相關報告材料的學習,加強對皮質學習算法細節的把握。
緒論
Introduction
1、皮質學習算法的歷史沿革
2、皮質學習算法的主要思想
3、報告的主要框架
George博士論文中的層級實時記憶算法
HTM: version I in George’s PhD thesis
層級實時記憶算法是模擬新皮層大腦結構,試圖模仿起功能的算法。首先,層級實時算法采用了層級結構,HTM算法由低層級到高層級依次提取low-level到high-level的不變特征,或者說更高層是低一層不變表示的重新組合。如果能夠在底層級學習到事物的一些最基本的模式,再通過高層級進行再組合,那么可以通過學習某些物體的模式時而達到將新事物的基本模式也包含的情況,即有較高的泛化能力。同時,通過層級結構,底層級學習一些low-level的不變特征或者子模式后,直接可以輸入到高層進行學習,高層級不用再對low-level的特征或者模式進行再學習,提高學習訓練的效率,也減小了存儲空間。
HTM算法另一個最突出的特點是引入了時間模式。之前很多deep model的層級結構大多只關注層級之間的連接(connections),這樣使得他們能夠提取較好的空間模式;但是他們沒有考慮到層級內部節點的連接,這種連接能夠學習到序列模式在連續時間內的轉移關系,進行序列記憶,在表征物體的空間模式集有交集的時候,通過時間相近,模式相似的準則可以增加物體識別分類的精度。下面,通過參考David的技術報告[]與George的博士論文[],將對George博士論文的HTM方面的理論進行詳述。
1、整體框架
如下圖1為一個三層的HTM示意圖,方塊表示節點。可以看出,HTM具有樹狀的層級網絡結構。高一層一個節點與其相鄰低一層的多個節點相連接, HTM的第一層節點直接與輸入相連(可以是overlapping的)。而某一個節點,不斷向下一層回溯,到輸入,他所處理的輸入范圍就是其感受域,如level one中的每個節點的感受域是1,level two的是2,level three的是4。
節點是HTM中記憶與預測的基本單元。在節點中,主要存有三種數據,C(coincidences的集合), G(temporal groups的集合,每個group實際上是coincidences的集合),transition probability matrix(為每個group中各個coincidence之間的轉移概率組成的矩陣)。
每一個處于中間層(除開第一層與最后一層)節點,都有唯一一個父節點,與多個子節點。HTM對空間模式的提取,依賴的是父節點對各子節點的子模式的pooling,而時間模式與序列記憶的實現,依賴于節點中不同的temporal groups以及其各coincidences組成的markov chains。通過記憶不同order的markov chains,可以由一個coincidences往前或者后推知另外coincidences發生的可能性,從而實現序列記憶。而每個group也是由這種coincidences之間轉移概率最大化分類,以獲得時間相近,模式相似的結果。
對于一個HTM模型,其識別的整體流程是:當某一層各節點分別接收來自其子節點的輸入時,開始進行識別,其結果作為父節點的部分輸入。而對于一個HTM模型的訓練學習,首先要對最低層進行訓練,訓練完畢后,再對高一層進行訓練,而輸入來自低層按識別流程處理得到的結果。下面幾節,將從單個節點的訓練與識別進行展開介紹。
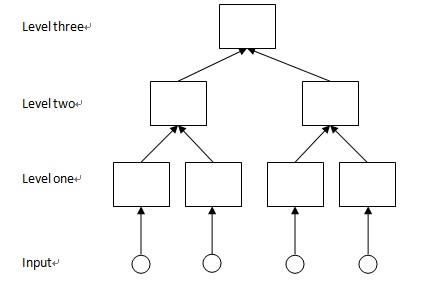
圖1 HTM結構示意圖
2、學習
在學習階段,大致分為3步,對新模式進行記憶,轉移概率矩陣的計算,對模式進行分組獲取temporal groups。
I,模式進行記憶。當一個節點接收到一個新的模式時,首先是將輸入模式與節點中已存在的模式進行比較(如,比較距離),如果該輸入與某個存在的模式足夠近,那么就激活該模式。如果沒有找到足夠近的模式,那說明這個輸入模式是一個新的模式,將他存入模式集中,以待后用。這就是模式的記憶。
II,轉移概率矩陣的計算。當一個模式被激活,回顧之前激活的模式,將矩陣中對應兩者轉移關系的位置自增1。當然,HTM也可以存儲多步的轉移,回顧數步以前被激活的模式,存儲其轉移關系。在所有模式輸入完畢,對轉移矩陣每行或每列(視存儲情況定)進行歸一化,得到轉移概率。
III,temporal groups的計算。根據轉移關系的統計,可以知道哪些模式轉移相對頻繁,而哪些模式之間轉移概率相對較大。Temporal groups的計算的原則就是基于此,選取一些轉移較頻繁的模式作為種子點,從該種子點向與其轉移概率最大的點進行生長,達到一定數目停止生長,從而實現temporal groups的分類。而每個group以及其coincidences之間組成的markov chain是模型序列記憶的關鍵。
需要注意的是,在訓練完畢一層之后,再訓練更高層時,首先利用識別流程,將前些已經訓練好的層級的結果輸出到更高層,進行學習訓練,但是這里,一般將concatenation的各輸入(子節點的輸出)中最大值位置設為1,而其他位置置為0(David處理方法是每個coincidences為#(子節點數目)維向量,每個元素存的是最大值位置索引,感覺這種省存儲空間)。這實質上是一種稀疏化的處理,之后在介紹Numenta里面的HTM與現在介紹的HTM的聯系和區別時還會提及。
3、識別
在識別階段,假設每個節點的C,G,transition probability matrix已經訓練好。一個節點的輸入過程一般分為兩步,首先計算對當前輸入,提取所有coincidences對該輸入的certainty;其次是計算對當前輸入,提取所有groups對該輸入的certainty。
I,提取coincidences的certainty。對于第一層的節點,這種certainty通常是通過考量輸入與模式之間的近似程度來實現,而對更高層,coincidences里面存的是各個子節點哪些temporal groups共同出現,所以這些子節點的temporal groups對該輸入的certainty共同組成該coincidence對該輸入的certainty。
II,提取groups的certainty。同理,groups里面是指哪些coincidences會共同出現,一個groups的certainty由這些coincidences的certainty共同組成(都是概率相乘)。
III,關于識別的一些思考
考慮上面公式(來自George論文,公式含義不細說),在序列記憶的情況下,實際上每個group的certainty不僅僅考慮了他包含的coincidences對他的貢獻,同時通過序列轉移情況,能夠知道某個coincidence在前面已有序列條件下,現在出現的概率,這種序列記憶能夠更好地反映出一個coincidence對某個輸入的certainty。當然,在David的報告中,大多數情況下以下圖中公式(4.4)為基本,沒有考慮多步的轉移。
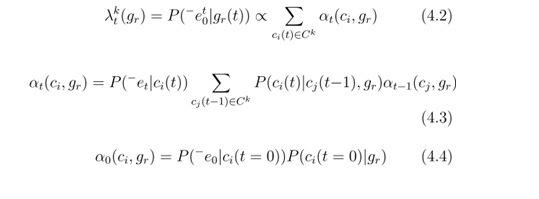
考慮下面示意圖2(參考David論文),一個類別可能主要有部分輸出節點中coincidences的certainty來確認,而這些coincidences只由部分子節點的groups共同生成,如此類推下去,可以知道一個類別的模式由部分最基本的模式組合表達,就印證了當系統學習到一些基本模式后,對于具有這些基本模式的事物具有泛化能力。
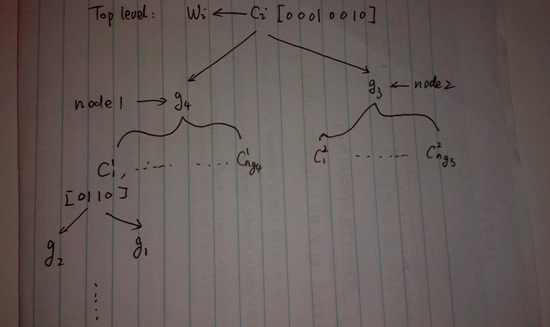
圖2 HTM泛化能力的示意解釋,見正文
注意這里將所有的模式對輸入的certainty都計算在內,這與訓練中只激活一個模式是有區別的,在訓練中如果將所有模式激活就無法得到轉移概率矩陣了。同樣這與Numenta白皮書里的cell激活方式也稍有不同,下面會再講。
4、總結
這一部分主要對George文章中的HTM算法進行基本的總結。通過對于兩篇文章的綜合,可以對于該HTM模型的所有細節具有比較清楚的認識,包括如何處理圖像(如按zig-zag對圖像序列化,圖像像素或者子塊或者對像素鄰域提取的特征如何輸入到節點)等都能有具象的認識。但這里只是回顧了一些主要的流程。核心點:通過高層對低層模式的再組合,提升系統的泛化能力;每個group實際上是對序列的記憶,轉移概率大小體現了模式之間在時間上相近程度。
Numenta白皮書中的層級實時記憶算法
HTM: version II in Numenta’s White Paper
該HTM版本[10]在George博士論文的版本上進行了一些修改與改進工作,在新版本中撤除了節點的概念,更多地去模擬新皮質的結構,引入了區域,細胞,樹突,突觸等生物學領域的概念。但是最基本的原則是沒有變化的,就是層級結構,記憶-預測等。當然,新版本里面還引入了稀疏離散表征(sparse distributed representation)的概念。
1、整體框架
在新版HTM中,層與區域的概念相似,如圖3中為一個層級(區域:region)的示意圖,該層級接收其下一層的信息,處理后,輸出送至更高層進行處理。每層有許多列(column)組成,形成二維平面(非必須),而每個列中包含有多種細胞(cell)組成。在每個列與輸入之間,有一個樹突(dendrite segment),它有許多潛在突觸(synapse),可能會與輸入中的部分子集相連接;而每個細胞有許多樹突,每個樹突也有許多潛在突觸,可能與其他細胞進行橫向連接。在圖3中沒有顯示出來。
對于HTM的識別、學習都分為兩個流程,首先對輸入進行稀疏離散表征,完成spatial pooling(sp),學習階段會對突觸的權值進行更新;其次,基于spatial pooler的結果,進行橫向信息傳遞、預測,完成temporal pooling(tp),學習階段也會對突觸的權值進行更新。Temporal pooling的輸出作為更高層的輸入,重復剛才的過程。識別和學習沒有明顯界限,在識別階段可以將學習的部分功能關閉即可。下面小節將以一個區域為例,對HTM的識別與學習進行比較詳細地介紹。
注:需要特別指出的是,每個column如果被激活(之后會解釋什么是激活狀態),那么它是能夠表征模式的部分含義的,對于一個輸入模式,就被一組稀疏的活躍column進行有效表征。但是我們知道,“ABCD”與“EBCF”中的模式B與C是不一樣的,那么在HTM中如何實現不同上下文的表征呢?HTM中,每個column擁有很多細胞,在不同的上下文時,激活的細胞是不一樣的,這樣就達到了能夠表征不同上下文中相同內容的目的。
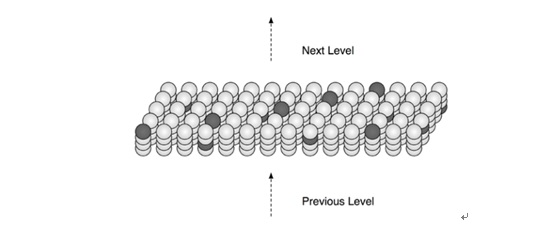
圖3 HTM一個區域(層級)的結構
2、Sparse Distributed Representation
在介紹sp與tp之前,首先要對稀疏離散表征進行描述。稀疏離散表征是HTM的重要基礎,序列記憶等都基于稀疏離散表征。稀疏離散表征是將自然界語言(如圖像,文本,音頻等)轉換為二進制序列,而且是稀疏的。稀疏離散表征的每一個活躍(值為1)的bit都能表達模式的部分含義,但是僅僅一個bit又是不夠的,只有整體才能表達一個完整的模式。稀疏離散表征具有很多很好的性質:
I,在比較時,只要兩個不同的稀疏離散表征具有一些相同的活躍bits,那么這兩個稀疏離散表征表達的模式具有一定的相似性。
II,在存儲時,可以對稀疏離散表征進行subsampling,而能較好地保留其表達含義。這樣節省了存儲空間。
III,不同的稀疏離散表征做OR運算后,為這些稀疏離散表征的組合,如果一個新的稀疏離散表征的活躍的bits來自于這個組合,那么可以肯定他在這個集合中的membership。一個有趣的現象是,當訓練了序列”ABC”“ABD”后,如果輸入“AB”,它所進行的預測就是“C”與“D”的組合。下面我將介紹如何得到稀疏離散表征。
IV,正是因為一個bit可能只表示非常少的模式信息,所以對噪聲不敏感,有些許bits不同的兩個模式可能也是相似的。
3、Spatial Pooler
首先,對于區域中的每個列(column)都有一個receptive field,來接收輸入中的子集,其樹突上的活躍突觸(權值大于一定閾值,初始化時權值在閾值附近進行隨機取值)將與輸入的bits連接,如果連接到活躍bit(=1)的活躍突觸數目大于一定閾值時,認為該column可以作為活躍column的備選。
然后,為了達到稀疏表征的目的,不希望太多的column能夠激活,所以在一定的抑制半徑(通過columns的平均receptive field計算)內,只有前n(如n=10,當然也可以用總數的百分比)才能被激活。這樣,將所有滿足條件的columns激活,得到的就是輸入的稀疏離散表征。
在學習階段,需要更新權值,一般希望特定的突觸對于特定的輸入具有響應,這樣達到不同模式具有不同稀疏表征的效果,所以使得活躍column的潛在突觸中,所有連接活躍bits(=1)的突觸權值自增,而連接不活躍bits(=0)的突觸權值自減。其他column的突觸權值不變。
當然,在sp中,有許多細節需要注意,比如說HTM希望所有的columns都要被用來進行一定模式的表征,所以那些因為覆蓋值(overlap,就是連接活躍bits的活躍突觸數目)長期不夠,與那些因為覆蓋值長期不能進入抑制半徑內前列的columns突觸權值進行boosting,即增加其權值。
4、Temporal Pooler
當輸入用稀疏離散表征后,得到活躍的columns,然后要進行temporal pooling。主要分為以下幾步:
首先,要對columns里面的細胞進行激活。細胞的激活分為兩種情況,第一種,區域之前沒有做出預測,那么,對于sp得到的激活columns中所有細胞進行激活;第二種,區域之前已經做出了預測,那么,在每個活躍column中判斷是否有細胞在前一時刻被正確預測,如果有,僅僅激活該細胞,說明符合當前上下文環境,如果沒有,那么將這一列的所有細胞進行激活,說明我還不清楚上下文環境是什么,所以所有上下文環境都有可能。而其他沒有被正確預測或者沒有再激活columns中的細胞保持或者變成不活躍。
其次,要進行預測。對于沒有被激活的細胞,觀察其連接的樹突,如果該樹突上連接活躍細胞的活躍突觸數目大于一定數目時,我們認為該樹突被激活,然后使得其連接的細胞被激活,當一個細胞存在多個樹突被激活時,進行OR運算。
在學習階段,為了防止細胞過多的活躍突觸,從而過多進行預測,HTM一般希望每個活躍column中只有一個細胞進行學習,在被正確預測了的細胞當中,首先計算該細胞通過活躍突觸連接的之前處于學習狀態的細胞數目,當其大于一定閾值時,進入學習狀態;而對于沒有被正確預測的細胞,選取連接活躍突觸數目最多的細胞進入學習狀態。對進入學習狀態的細胞,將其活躍突觸權值自增,其他突觸權值自減。而對于一些之前被預測,當前沒有被預測的(沒有激活的)細胞,說明之前預測有問題,所有該細胞連接的突觸自減。對于被正確預測的細胞,我們希望觀察它們是否做出了正確的預測,對于他們權值的強化更新,所以先存在隊列中,待到前進一定的time step再進行處理。可以看出,如果一個細胞被正確預測,HTM會強化這種前后細胞的轉移關系,強化記憶序列關系。
注:在文章中,對預測的性質進行了很多解釋。一個重要的點就是預測使得層級的輸出變得更加穩定,這是因為輸入模式可能連續變化,但是由于存在序列記憶,HTM會對輸出進行一步或者多步預測,變化的輸入可能只導致部分輸出發生變化,而其中正確預測而激活的細胞,以及那些相同的多步預測使得輸出變化比較小。當然更高層的輸出更加穩定,在上一個版本的HTM里也存在,因為變化的模式,可能是同屬于一個markov chain,一個group,所以在更高一層就有相似的輸出了。
5、與Version I的內在聯系與主要區別
在這里,主要分析一下第二章與第三章所介紹的兩個HTM版本有什么內在的聯系,又存在如何的區別。
I,結構。首先層級結構相似自不必再說。我們看micro-structure。一乍看,前一個版本里面的存儲記憶的基本結構是節點,這里是column。實際上兩者是很相似的,這里的columns相當于之前的coincidences,而column中的細胞就是這個coincidences的不同狀態,就比如之前的coincidences可以通過state-splitting劃分到不同的markov chain一樣。而細胞之間的突觸,實際上是group中的markov chain。如下圖4,是將一個節點的C,G轉換為各種細胞之間信息的傳遞的結構,這明顯地揭示了與新版本的相似之處。區別在于,group這個概念不再有,隱含在了稀疏離散表征里面,而且在新版本里面,突觸的連接可以說也是稀疏的,二值化后的突觸權值使得各細胞間不會所有信息都進行傳遞。
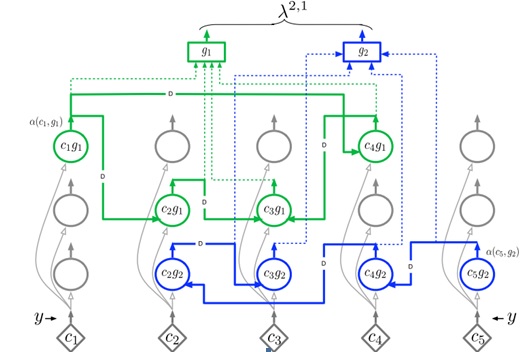
圖4 來自于George博士論文
II,功能。結構的相似性決定了功能上也基本相似,序列記憶一個通過突觸權值實現,一個通過markov chain來實現。稍微不同的是,新版本對輸入進行了稀疏離散表征,而在老版本中,如圖中,y會計算所有coincidences的certainty。這也是兩個版本的最大區別:稀疏離散表征。
6、總結
在這章,主要介紹了Numenta白皮書中介紹的HTM模型,對稀疏離散表征,空間沉積池(spatial pooler),時間沉積池(temporal pooler)進行了介紹,可以看出其對空間模式的提取是通過空間沉積池進行稀疏離散表征實現的,不同的column具有不一樣的表達部分模式的含義,不同的組合就是表征不同的模式;而時間模式是通過細胞橫向間的突觸權值實現的,通過加強前后模式之間的轉移權值,來實現對序列的記憶。該HTM模型除了引入稀疏離散表征,將markov chain,group等概念隱含到突觸權值上,但是,從實質上與George中的模型沒有太多的區別,都為層級結構,都能夠進行記憶-預測。
層級實時記憶算法的實現
The implementation of HTM
該部分內容還沒有進行完全,希望在之后的工作中逐漸豐富。
1、Encoder
基本思想是當給定一個標量用多少個bits表示,在最小值到最大值的區間范圍,以及總共輸出多少bits,就能夠根據在區間內的任意輸入值,根據其標量值所在位置,計算出輸出中那些bits為1。這樣,在數值上相近的標量,在二進制表達上也比較相似。
對于二維圖像如何編碼,是一個比較困難的問題,因為他除了有灰度大小表示一定的含義外,同時也有像素間上下文的關系,所以在進行二進制化時是一個比較困難的事情。這部分需要繼續學習。
2、Spatial Pooler
3、Temporal Pooler
4、CLA Classifer
5、總結
總結與展望
通過學習Numenta的白皮書可以知道,現發布的HTM模型還只是利用單層去解決問題,當然實現多層應該比較簡單。同時該層主要是模擬了新皮質的第3層功能,也沒有反饋,行為控制等等功能,以后的工作應該是逐步完善HTM,使得其結構功能盡可能的相似。
通過學習,對于HTM的發展演變,模型的理論,結構,功能,如何進行學習,識別,都有比較好的理解。但是還不足以發現文章的問題,我覺得自己的工作之后是要不斷通過進行實驗,來印證理論的同時,發現HTM的問題在哪里,所以下一步的工作重點將傾向于此。同時,我覺得HTM的優勢是不是在于他不僅在層級之間有連接,同時,也增加了層級內部的連接,所以是不是需要看一些其他的模型來對比一下呢?
一個問題:在George論文中的HTM能夠利用Belief Propagation理論來推導inference等的過程,那么能不能同樣用到Numenta現行的HTM模型中呢?
參考文獻
[1] D. George, "How the Brain Might Work: A Hierarchical and Temporal Model for Learning and Recognition",Ph.D Thesis, Stanford University, June 2008.
[2] D. George and J. Hawkins, "A Hierarchical
[3] D. George and J. Hawkins, "Belief Propagation and Wiring Length Optimization as Organizing Principles for Cortical Microcircuits", Technical report, Redwood
Neuroscience Institute.
[4] Jeff Hawkins, Dileep George and Jamie Niemasik, "Sequence memory for prediction, inference and behaviour", Philosophical Transactions on the Royal Society B, 2009.
[5] http://vicarious.com/
[6] http://www.kurzweilai.net/vicarious-announces-15-million-funding-for-ai-soft ware-based-on-the-brain
[7] http://numenta.com/grok/
[8] D. Maltoni, Pattern Recognition by Hierarchical Temporal Memory , Technical Report, DEIS - University of Bologna technical report, April 2011.
[9] E.M. Rehn and D. Maltoni, Incremental Learning by Message Passing in Hierarchical Temporal Memory , Neural Computation, vol.26, no.8, pp.1763-1809, August 2014.
[10] J. Hawkins, S. Ahmad and D. Dubinsky, "Hierarchical Temporal Memory including HTM Cortical Learning Algorithms",
hierarchical-temporal-memory-cortical-learning-algorithm-0.2.1-en.pdf
[11] https://github.com/MichaelFerrier/HTMCLA
[12] https://sourceforge.net/p/openhtm/
[13] https://github.com/numenta/nupic/wiki