
�����M(j��n)һ���ц�Ƭ�C(j��)�ĝ��ܰl(f��)�]���O�ޣ���һֱ�댑��(g��)����ц�Ƭ�C(j��)�������YԴ���ù⣬����������Նε���������(zh��)�еķ�ʽ�����y��MCU��CPU�r(sh��)�g��������ã�����ʹ��ܛ���ӕr(sh��)����(sh��)��(sh��)�H�Ͼ����ڟo�^��������CPU�ĕr(sh��)�gʲô���鶼��������?y��n)�CPUһֱ��ѭ�h(hu��n)�ȴ����l���Y(ji��)�����@�ஔ(d��ng)�ں���(sh��)�������ˡ�
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
��
 �ɹ�ͬ�r(sh��)�\(y��n)������(g��)��ˮ������̫���ˣ��������@��(g��)��(n��i)�˵�֧������Ϳ��Ԅ�(chu��ng)����đ�(y��ng)�ó����ˣ�ʹ�Ã�(n��i)���ṩ�ľ��̄�(chu��ng)������(sh��)����Ԅ�(chu��ng)��N����(g��)���̣���(d��ng)Ȼ�ˣ�����ڃ�(n��i)��ɽ��ܵķ�����(n��i)�����Ã�(n��i)����亯��(sh��)����Ԅ�(d��ng)�B(t��i)��Ո(q��ng)��ጷŃ�(n��i)���ˡ���Ҳ���Þ�DELAY()�@�N���M(f��i)CPUЧ�ʵ����������ܾ��ˡ�
�ɹ�ͬ�r(sh��)�\(y��n)������(g��)��ˮ������̫���ˣ��������@��(g��)��(n��i)�˵�֧������Ϳ��Ԅ�(chu��ng)����đ�(y��ng)�ó����ˣ�ʹ�Ã�(n��i)���ṩ�ľ��̄�(chu��ng)������(sh��)����Ԅ�(chu��ng)��N����(g��)���̣���(d��ng)Ȼ�ˣ�����ڃ�(n��i)��ɽ��ܵķ�����(n��i)�����Ã�(n��i)����亯��(sh��)����Ԅ�(d��ng)�B(t��i)��Ո(q��ng)��ጷŃ�(n��i)���ˡ���Ҳ���Þ�DELAY()�@�N���M(f��i)CPUЧ�ʵ����������ܾ��ˡ�
��
���˸����@���(y��n)�C�@һ�c(di��n)���������WINDOWS�´��_VC6.0��������C�Z�Ծ��g�������δ��a���£�
��
#include <stdio.h>
void main(void)
{while(1) ;}
��
��˼��CPU���������ڵȴ�����£��@����a��(hu��)���ĵ�����CPU�r(sh��)�g��
��
�𰸕�(hu��)����(j��)��ͬ�C(j��)�Ͷ���ͬ������džκ�CPU��Ԓ���@��Ԓ��(hu��)���ĵ�CPU�ӽ�100%�ĕr(sh��)�g��������p��CPU���tֻ���ĵ�50%���ң���?y��n)��@�δ��aֻ�\(y��n)��������һ��(g��)�ˣ�����һ��(g��)��߀�������e�����飬�؈D���£�
��
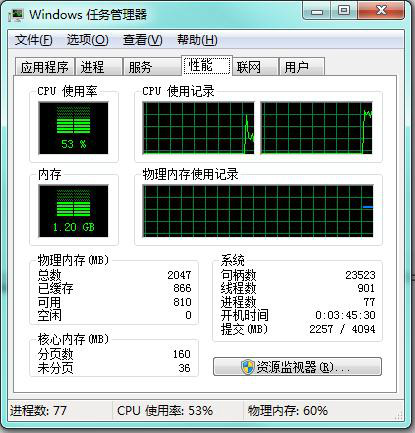
Ȼ������Ԝyԇ�����@����a��
#include <stdio.h>
#include <windows.h>
void main(void){while(1)
Sleep(100);
}
��
�@�δ��a��(sh��)�H��Ҳ��ʲô����������������{(di��o)��Sleep()����(sh��)�����ӕr(sh��)100�������с���Ȼ���^�m(x��)˯�X���F(xi��n)��������ٴ��_�΄�(w��)��������һ��CPU�r(sh��)�g���˶��٣����ǻ�������CPU�r(sh��)�g����
��
��ʲôͬ�ӵ�ʲô���鶼��������eզ���@ô���أ��@����?y��n)�ʹ����Sleep()�@��(g��)����(sh��)��WINDOWS����ϵ�y(t��ng)�����ṩ�ģ��{(di��o)��Sleep()֮�� WINDOWS����ϵ�y(t��ng)�Ԅ�(d��ng)�����@��(g��)��������ˣ����Ǖ��r(sh��)�ӵ�һ߅���ܣ���Ȼ��CPUȥ��(zh��)���������ȵ��r(sh��)�g���ˣ�����ϵ�y(t��ng)�ٰ��@�γ���֏�(f��)�^�m(x��)��(zh��)�У��@�ӵ�ԒCPU�Ϳ��Եõ���ֵ������ˣ�Ҳ�����f�������һ�KCPU����“ͬ�r(sh��)”��(zh��)�ж���(g��)�΄�(w��)������Ӱ푣����@�����f��“ͬ�r(sh��)”������ͬ�r(sh��)��(zh��)�У�CPUÿһ�r(sh��)��ֻ����һ���£�������ٶ������Ԓ�Ϳ����˸е�������ͬ�r(sh��)��(zh��)�ж��(xi��ng)�΄�(w��)�ˣ����ǵģ�����ϵ�y(t��ng)���Ǟ��˽�Q���΄�(w��)��(zh��)�ж����ġ���Ȼ����ϵ�y(t��ng)�@ô���棬�ɲ�������Ƭ�C(j��)Ҳ��ˬһ���أ����ǿ϶��ġ�����ͽ�B��νo��Ƭ�C(j��)����(g��)����ϵ�y(t��ng)����
��
/************************************************************************************/
���������£����������������ˌ�������ϵ�y(t��ng)����횵���һ������Փ�Լ����g(sh��)���A(ch��)��
��Ƭ�C(j��)����Ŀ���http://www.zg4o1577.cn �˽��������������IJ��ϣ�
��Ƭ�C(j��)����Ŀ���http://www.zg4o1577.cn �˽��������������IJ��ϣ�
//1 C�Z�Ծ��̻��A(ch��) ������
//2 ��(sh��)��(j��)�Y(ji��)��(g��u)��Փ ��һ��˃�
//3 ����ϵ�y(t��ng)ԭ�� ���ɽ����ɰ��X
//4 Ӌ(j��)��C(j��)�M��ԭ���Լ���Ƭ�C(j��)ԭ������(y��ng)�� ���ɽ��
//5 �R���Z�Ծ��̻��A(ch��) ��һ���ă�
//6 һ�݈�(ji��n)�ֵ��� �����ٽ��Լ������������Ǻ�
/*************************************************************************************/
��
�@ô����ô�W(xu��)��ȥ�ČW(xu��)���������҂�(g��)�����]�ĕ��Σ��H��������
��
1. C�Z���DZ��Ҫ��(hu��)�ģ�����Ҫ�쾚���T��”�A(y��)���g����“����Ҫ����ģ�K�����̱��Ҫ��Ϥ��ָ���C�Z�Ե�һ���裬�ڲ���ϵ�y(t��ng)Դ�a����ָ��ǝM���w�ģ����Ե���������Փ���A(ch��)�����]����ġ�C Primer Plus�� ���� Stephen Prata���������v�ă�(n��i)���ɜ\����Z��������٣�����_ʼ�����F(xi��n)��߀�r(sh��)���r(sh��)��Ҫ���^�����_��(sh��)��һ�����e(cu��)�ĺÕ���

���⣬�W(xu��)��(hu��)��C�Ļ����Z��֮����߀��Ҫ��(hu��)һ�c(di��n)�c(di��n)���̼����Լ�����Ҫע��Ć��}֮ģ����]�пյ�Ԓ�����C���Ҿ��̡��͡�C�����cȱ�ݡ����@�ɱ�����C�����I(l��ng)������Ľ�(j��ng)��֮�������ſ�����Ĺ�����(hu��)�����L�M(j��n)������߀��Ҫ�Խ�(j��ng)���ô��a������


2. ����ϵ�y(t��ng)����Ĕ�(sh��)��(j��)�M����ʽ�����Ԕ�(sh��)��(j��)�Y(ji��)��(g��u)����Փ����A(ch��)�ģ�������ö��Ô�(sh��)��(j��)�Y(ji��)��(g��u)���ܿ�������ĺ��x����Ҳ��Ҫ��є�(sh��)��(j��)�Y(ji��)��(g��u)ȫ��ͨ�����]��(y��n)ε���汾�ġ���(sh��)��(j��)�Y(ji��)��(g��u)�������^������㷨�����Âδ��a�������ģ�

3. ���˾��̻��A(ch��)֮����߀���Ҫ���ò���ϵ�y(t��ng)�Ļ���ԭ���������΄�(w��)֮�g����ô�ГQ�ģ���(n��i)������ô�����Ķ��ö������]������ϵ�y(t��ng)-�����c�O(sh��)Ӌ(j��)ԭ����
��

4. �R���Z�ԡ���ʲôҪ�W(xu��)�R����������Щ�˕�(hu��)�W(xu��)�ÅR���y���⣬���ҬF(xi��n)��C�Z���ѽ�(j��ng)���Ժܷ���ؾ����ˣ����Բ���W(xu��)�R�����䌍(sh��)C�Z������ô���㏊(qi��ng)�����߀��Ҫͨ�^���g���D(zhu��n)�Q��R���Z�����ɅR���D(zhu��n)�Q��C(j��)���a�������ڙC(j��)���Ј�(zh��)�С������f�������˅R��֮����һ����(hu��)��(du��)”���a����ô��CPU�����(zh��)�е�“�@��(g��)�܌W(xu��)���}���M(j��n)һ�����˽⡣���⣬���W(xu��)�R����߀�挑����һ��(g��)����ϵ�y(t��ng)��(n��i)�ˁ�����?y��n)����ϵ�y(t��ng)����͌���Ҫֱ�Ӳ���CPU�Ĵ����ģ�C�Z�ԟo����(sh��)�F(xi��n)��ֻ���ÅR���������������όӵ�C�Z���{(di��o)�á��R���ĕ��ܶ࣬�@��Ͳ���B�ˣ���һ��ȥ�����ς�(g��)�����ھʹ�������ˡ�
��
��
5. ������߀Ҫ����Ӌ(j��)��C(j��)ԭ���Լ���Ƭ�C(j��)���䌍(sh��)��Ƭ�C(j��)����һ�_(t��i)鎸���Ӌ(j��)��C(j��)����Ì�(du��)CPU�Ĵ�������(sh��)��(j��)��������ַ�������Լ���(zh��)�з�ʽ�@Щ��һ�����˽���У��@����ĕ�Ҳͦ��ģ����^��B�ɱ���(g��)���X�Ì���ͦ�õĕ����n���e�x��������Խ֮����1��2�����@�������w�Ͻ�B�˸�(j��)�Z������ô����CPU�����(zh��)�еģ�����Ҳ��(du��)CPU��(n��i)���Y(ji��)��(g��u)����һЩ��B������Щ�n��(n��i)�̲Č��úã��пտ���ȥ��һ�¡�
��


��
��
����Bһ����Ƕ��ʽ��(sh��)�r(sh��)����ϵ�y(t��ng)UCOS II�����@������B��UCOS II�@��(g��)����ϵ�y(t��ng)�ă�(n��i)��Դ���a�Լ���(sh��)�F(xi��n)ԭ�����Ҿ��Ǐ��@�����ЌW(xu��)�������ӌ�һ��(g��)�����õIJ���ϵ�y(t��ng)��(n��i)�ˡ�

�������]�ꮅ�������M(j��n)�����c(di��n)~~~~~~~~~~~~~~~~~
��
/**************************************************************************************/
ʲô�Dz���ϵ�y(t��ng)���䌍(sh��)����һ��(g��)���� �@��(g��)������Կ���Ӌ(j��)��C(j��)�������YԴ����(du��)�YԴ�M(j��n)�з��䣬����CPU�r(sh��)�g����(n��i)�棬IO�˿ڵȣ���һ��Ҏ(gu��)�t����o����Ҫ���M(j��n)�̣��M(j��n)�̣�Ҳ����һ��(g��)�����ԆΪ�(d��)��(zh��)�У��������Ԅ�(d��ng)����CPU���Ԉ�(zh��)�ж���(g��)�������P(gu��n)���΄�(w��)�����Օ��еĽ�B��һ��(g��)����ϵ�y(t��ng)��Ҫ�߂��Ă�(g��)Ҫ�أ��M(j��n)���{(di��o)�ȡ���(n��i)�������IO�������ļ�������
��
����ô�ӿ���CPUͬ�r(sh��)��(zh��)�ж���(g��)�΄�(w��)�أ���������һ�����CPU��(zh��)�Іε���������(hu��)��MAIN����(sh��)�_ʼһֱ���؈�(zh��)����ȥ��CPU������һ��(g��)��PC�ļĴ�����Ҳ���dz���Ӌ(j��)��(sh��)���������h(yu��n)ָ����һ�lҪ��(zh��)�е�ָ��Ĵ�ŵ�ַ����?y��n)����?sh��)��r��ָ�����l��(zh��)�еģ�����PC�Ĵ���Ҳֻ�Ǻ��εؼ�һ�����Դ�Ҷ�����”����Ӌ(j��)��(sh��)��“����PC�Ĵ��������c(di��n)Ҳ�S�҂��������c(di��n)���£������˞��PC�Ĵ���ָ������һ�γ������ڵ�ַ����CPU�����Ԅ�(d��ng)���ܵ���һ�γ�����ô�������������҂������@�������Ǜ]�e(cu��)��CPU�_�����ܵ��e�˵��I(l��ng)��ȥ��(zh��)�д��a�ˣ����}�ǣ���ô�������^�m(x��)��(zh��)�У��Q��Ԓ�f��PC�Ĵ�����׃֮��CPU �ѽ�(j��ng)��֪�������@�γ����(zh��)�е������ˣ��༴�ܲ����ˣ�������˾����L(f��ng)�~���������@���}�韩������Q���@��(g��)���}���ƺ����c(di��n)���^�ˡ���
��
�ðɣ��҂���������һ��(g��)�����ƵĆ��}�����dž�Ƭ�C(j��)�ڈ�(zh��)�д��a�ĕr(sh��)��ͻȻ��һ��(g��)�Д���̖(h��o)�^���ˣ���Ƭ�C(j��)�R�Ͼ�ƨ�ƨ��ܵ��Д����(w��)��������ȥ��(zh��)���ˣ���(zh��)���ꮅ֮����֣�������ô߀ӛ���ܻ�ԭ���ĵط���������OH NO .������ô�k���ġ��䌍(sh��)�@��߀Ҫ��B����һ��(g��)�Ĵ�����SP�ģ�����STACK POINTER�ї�ָᘣ��@��(g��)ָ�ָ��һ��(g��)��(n��i)��ĵ�ַ����������һЩ��(sh��)��(j��)�����ȣ���Ƭ�C(j��)�����Д���̖(h��o)�ĕr(sh��)�����ͰѮ�(d��ng)ǰ��PC�Ĵ�����ֵ���浽SP��ָ�ĵ�ַ���@���ஔ(d��ng)����ӛס�ˮ�(d��ng)ǰ��(zh��)�еĵط����������c(di��n)���o(h��)��Ȼ��PC�Ĵ�����ָ���Д����(w��)����ĵ�ַ����һ��(g��)�r(sh��)��CPU���Ԅ�(d��ng)��(zh��)���Д����(w��)��������Ĵ��a�ˣ���(zh��)���ꮅ֮���Д����(w��)�����{(di��o)����һ��(g��)ָ�RETI���@�lָ��з���ָ��ں���(sh��)�Y(ji��)��֮���{(di��o)�ã�����(hu��)�Ԅ�(d��ng)��SPָ�ָ��ĵ�ַ��ֵȡ�����ŵ�PC�Ĵ������棬Ȼ��CPU�͕�(hu��)�Ԅ�(d��ng)�ص�֮ǰ����ĵط��^�m(x��)��(zh��)���ˣ������@��(g��)ԭ�����҂����Իص�����Ć��}�����ȣ�CPU�Ѯ�(d��ng)ǰ��PC����������Ȼ���PCָ��e�γ����ַ��CPU���ܵ��e�˵��I(l��ng)��ȥ��(zh��)���ˣ���(zh��)������֮���҂�����SPָ��ă�(n��i)�ݷŻ�PC���@���{(di��o)��RETָ��֮��CPU�͕�(hu��)�ص�ԭ���ĵط��^�m(x��)��(zh��)���ˣ���ò���@��(g��)���}�����ؽ�Q�ˣ���
��
����߀��һ��(g��)�P(gu��n)�I�Ć��}��CPU�ڈ�(zh��)�Ю�(d��ng)ǰ���a�ĕr(sh��)�� CPU�������еļĴ���������Į�(d��ng)ǰ�@��(g��)�������õ���ֵ���������ӷ��ĕr(sh��)���õ�PSW�Ĵ������M(j��n)λ��(bi��o)־λ������˕r(sh��)�ГQ���e���΄�(w��)�����ٻص���(d��ng)ǰ����ĕr(sh��)���@Щֵ����(hu��)����׃��CPU��(hu��)�����yȻ��ֱ�����w������Q�@���}ͬ��Ҫ��SPͬ�W(xu��)�����ГQ�΄�(w��)�ĕr(sh��)���҂������мĴ��������뵽SPָ��ĵ�ַ���Q���뗣������ÿ���뗣SPָᘵ�ֵ����(hu��)��һ���ߜpһ��ҕ��ͬCPU��������Ҫ�֏�(f��)�ĕr(sh��)�͏�SPָ��ĵ�ַ���ΰ�ֵȡ�����Ż�ԭ���ĵط����Q�鏗�����������ŏ�����ַ��PC�Ĵ�������һ�r(sh��)�̣�CPU�Ԅ�(d��ng)�ܵ�ԭ���ĵ�ַ�^�m(x��)��(zh��)�У���CPU�ĽǶȿ�����]�аl(f��)���΄�(w��)�ГQһ�ӣ�һ�����f���^�m(x��)���������CPU�Ĉ�(zh��)���ٶȉ�죬�ГQ�ٶ�Ҳ��죬�@�ӾͿ��Խo�˸��XCPUͬ�r(sh��)�ڈ�(zh��)�кܶ��΄�(w��)���@���Dz���ϵ�y(t��ng)�����������ԭ����
��
SO�������ԭ�����҂����ȁ��́팍(sh��)�F(xi��n)���ε��΄�(w��)�ГQ���@����y�c(di��n)�����ڣ���(zh��)���@һ��(d��ng)�����Ҫ����CPU�ļĴ�������C�Z���ǟo����(sh��)�F(xi��n)�ģ��@���Ǟ�ʲôҪ�õ��R����ԭ���ˣ����в���ϵ�y(t��ng)����Ӵ��a�����ÅR���Z�Ԍ�(sh��)�F(xi��n)�ģ���t�����o����(sh��)�F(xi��n)�΄�(w��)�ГQ������Ҫ��B�R������Ďחl���P(gu��n)ָ�PS:�mȻÿ�NCPU�ąR������ͬ�����ǻ���ԭ��߀����ͨ�ġ�
��һ�l��CALL������(sh��)�{(di��o)��ָ���(d��ng)�҂�Ҫ�{(di��o)��һ��(g��)����(sh��)�ĕr(sh��)�͕�(hu��)�õ�CALL�@�lָ�����(zh��)���ُĂ�(g��)��(d��ng)������һ���ȰѮ�(d��ng)ǰ��PCֵ�������������F(xi��n)�����o(h��)���ڶ�����Ҫ�{(di��o)�õĺ���(sh��)����ڵ�ַ�͵�PC���@�ӣ�����һ�r(sh��)�̵����ĕr(sh��)��CPU���Ԅ�(d��ng)���D(zhu��n)���ض��ĺ���(sh��)��ڵ�ַ�_ʼ��(zh��)���ˡ�
�ڶ��l��RET/RETI����(d��ng)һ��(g��)����(sh��)��(zh��)���ꮅ�ĕr(sh��)����Ҫ���ص�ԭ���(zh��)�еĵط����@�r(sh��)���Ҫ�{(di��o)�� RETָ����Дຯ��(sh��)�з��صĕr(sh��)���{(di��o)��RETIָ�������SPָ��Ĕ�(sh��)��(j��)������һ���{(di��o)��CALL�r(sh��)������ǂ�(g��)��ַԭ����PC���@�ӣ���(d��ng)��һ�r(sh��)�̵����ĕr(sh��)��CPU�͕�(hu��)���ص�ԭ���ĵط��ˡ���(sh��)�H�Ϻ���(sh��)�{(di��o)���^�̾����@�ӵģ������Еr(sh��)��һЩ���κ��̵ĺ���(sh��)��Ը��#define�궨�x����������?y��n)��@�ӌ������Ͳ���ʹ���{(di��o)��/�����^�̣���(ji��)ʡ�˕r(sh��)�g��
����/�ėl��PUSH/POP���@�ɂ�(g��)ָ���ǃ��ֵܣ����뗣���������P(gu��n)�ڶї��������f��һ�£��ї��@�N�Y(ji��)��(g��u)�����Ծ��Ǻ��M(j��n)�ȳ�������B�P��һ�ӣ����B��ȥ�ıP�ӕ�(hu��)������ȡ�����@�Nԭ���dz����ã�����һ�º���(sh��)Ƕ�ĕr(sh��)��l(f��)����һ�У��������õ��@�N˼·��PUSHָ���õ��ѼĴ�����ֵ��������������(hu��)��ֵ�����浽SPָ�?bi��o)�ָ�ĵط���POPָ��t�є�(sh��)��(j��)��SP��ָ�ĵ�ַ�֏�(f��)��ԭ���ļĴ����С�
��
���@�חlָ��҂��Ϳ��Ԍ���һ��(g��)�΄�(w��)�ГQ����(sh��)�ˣ����^��֮ǰ߀Ҫ�f��һ��ʲô���˹��ї����䌍(sh��)�ϣ�һ��(g��)�����ڈ�(zh��)�еĕr(sh��)������(hu��)�õ�һ�K��(n��i)����g���ڱ�����N׃���������{(di��o)�ú���(sh��)�ĕr(sh��)���@�K�ط���(hu��)���ڱ����ַ�Լ��Ĵ��������ڈ�(zh��)��һЩ��(f��)�s�㷨�ĕr(sh��)�����CPU�ļĴ����ѽ�(j��ng)�����ˣ��@�K�ط�Ҳ��(hu��)�����R�r(sh��)���g׃���Ĵ�Ņ^(q��)�����⣬����һ��(g��)����(sh��)���f����(sh��)�ĕr(sh��)����:printf(a,b,c,d,e....)���������(sh��)�^�࣬����ą���(sh��)Ҳ��(hu��)�ȴ�ŵ��@�K�ط��������f���@�K�ط��������@��(g��)����Ă}��һ�ӣ������Ҫ�õĖ|����������چε������У��@Ȼ�@���Û]���}����������Ƕ�������Ԓ�����}�́��ˣ���?y��n)���������΄?w��)�����ljK�^(q��)�����f�΄�(w��)����Ė|���͕�(hu��)�����΄�(w��)���_����CPUһ���Ӿͯ����ˡ�����Q���k�����ǣ�ÿ��(g��)�΄�(w��)���o���ṩһ�K���õą^(q��)���@�K���Å^(q��)��ͽ��˹��ї���ÿ��(g��)�΄�(w��)����һ�ӣ����C�˲���(hu��)��_ͻ��
��
PS����?y��n)?1��Ƭ�C(j��)�ă�(n��i)��̫С�������o����(sh��)�F(xi��n)���΄�(w��)����(sh��)�F(xi��n)��Ҳ����(sh��)�ã�����Ӳ��ƽ�_(t��i)���x����AVR��Ƭ�C(j��)ATMEGA16����1KB��(n��i)�棬��(y��ng)ԓ�����ˣ����˃���r(sh��)�g��AVR�ąR��ָ���һ��
���ȣ���(d��ng)��Ҫ�ГQ�΄�(w��)�ĕr(sh��)��Ҫ�ȰѮ�(d��ng)ǰ�����мĴ���ȫ���뗣����AVR��Ƭ�C(j��)����32��(g��)ͨ�üĴ���R0-R31��߀��PCָᘣ�PSW�����B(t��i)�Ĵ������@Щ��Ҫ�뗣��������Ҫ�ă�(n��i)��ͦ��ġ��F(xi��n)�ڵľ��g����֧���ھ��R����������C�Z������Ƕ��?y��n)R���Z�ԣ�����ö࣬�����Һ궨�x��һ�M�뗣������PUSH_REG()����������PUSHָ���32��(g��)�Ĵ���ȫ���뗣
#define PUSH_REG() \
{_asm("PUSH R0\n\t" "PUSH R1\n\t" "PUSH R2\n\t" "PUSH R3\n\t" \
"PUSH R4\n\t" "PUSH R5\n\t" "PUSH R6\n\t" "PUSH R7\n\t" \
"PUSH R8\n\t" "PUSH R9\n\t" "PUSH R10\n\t" "PUSH R11\n\t" \
"PUSH R12\n\t" "PUSH R13\n\t" "PUSH R14\n\t" "PUSH R15\n\t" \
"PUSH R16\n\t" "PUSH R17\n\t" "PUSH R18\n\t" "PUSH R19\n\t" \
"PUSH R20\n\t" "PUSH R21\n\t" "PUSH R22\n\t" "PUSH R23\n\t" \
"PUSH R24\n\t" "PUSH R25\n\t" "PUSH R26\n\t" "PUSH R27\n\t" \
"PUSH R28\n\t" "PUSH R29\n\t" "PUSH R30\n\t" "PUSH R31\n\t" ); }
���ꗣ�����Ҫ���o(h��)��(d��ng)ǰ�����SPָᘣ��Ա��´���Ҫ���صĕr(sh��)�����ҵ�ԓ�˹��ї��ĵ�ַ��
OS_LastThread->ThreadStackTop=(OS_DataType_ThreadStack *)SP;
��
��
�@һ����C�Z�ԾͿ��Ԍ�(sh��)�F(xi��n)�ˡ�
�����P(gu��n)�ڮ�(d��ng)ǰ�@�γ���ĬF(xi��n)�����DZ��o(h��)���ˣ�Ȼ���ҵ�Ҫ�ГQ�����΄�(w��)���˹��ї���ַ�������x�oSPָᘣ����£�
SP=(uint16_t)OS_CurrentThread->ThreadStackTop;
��
��
�������뗣���Z����ֻ࣬�dz������Ҫ�෴��
POP_REG();
������Ҫ�{(di��o)��һ�l����Ҫ��ָ���ˣ���������һ����CPU�ԹԵ��ГQ�΄�(w��)�ˣ�
_asm("RET\n\t");
��
��
�{(di��o)�÷���ָ����͏�SP����ȡ������(sh��)��ַ�ŵ�PC��ע����ȡ�����DŽ�������SPָ���ַ�ĺ���(sh��)��ڣ���������(hu��)���ص����΄�(w��)��(zh��)�С�
���@�ӣ�һ��(g��)����ϵ�y(t��ng)��������ĵ�”�΄�(w��)�{(di��o)����“��ģ�;��@�Ӻ��ε،�(sh��)�F(xi��n)�ˣ�����ϵ�y(t��ng)���������ĸ��΄�(w��)�ГQ���P(gu��n)�����鵽���Ҫ�{(di��o)�õ��@��(g��)�΄�(w��)�{(di��o)�������F(xi��n)���҂���(sh��)�F(xi��n)�{(di��o)�����ˣ��ஔ(d��ng)�ڳɹ���1/3��������������ǿ��]��ʲô��r���{(di��o)���@��(g��)�{(di��o)������
��
�{(di��o)�Ȳ�������(sh��)�F(xi��n)���{(di��o)�ȣ�߀Ҫ�^�m(x��)���]�{(di��o)�Ȳ��ԣ�����ʲô��r����Ҫ�{(di��o)����Щ�΄�(w��)���{(di��o)�Ȳ��Էֺܶ�N�����dȤ�Ŀ���ȥ���DZ�������ϵ�y(t��ng)ԭ���������ҵ�Դ���a����ʹ����”��ռʽ��(y��u)�ȼ�(j��)�{(di��o)��+ͬһ��(y��u)�ȼ�(j��)�r(sh��)�gƬ݆ԃ�{(di��o)��“�ķ�����
���^��ռʽ��(y��u)�ȼ�(j��)�{(di��o)����һ�N��(sh��)�r(sh��)�{(di��o)�ȵķ������ڌ�(sh��)�r(sh��)����ϵ�y(t��ng)�г��ã��@�N������ԭ�����ǣ�����ϵ�y(t��ng)���κΕr(sh��)��Ҫ���C������߃�(y��u)�ȼ�(j��)���ǂ�(g��)�΄�(w��)̎���\(y��n)�БB(t��i)�������ӛ���\(y��n)������(y��u)�ȼ�(j��)��2���΄�(w��)����?y��n)�һЩ���?h��o)���_(d��)����(y��u)�ȼ�(j��)��1���ǂ�(g��)�΄�(w��)�����������̎�ھ;w�B(t��i)���@�r(sh��)����ϵ�y(t��ng)�ͱ���R��ֹͣ�΄�(w��)2���ГQ���΄�(w��)1���ГQ���@�Εr(sh��)�g��ҪԽ��Խ�á�
���r(sh��)�gƬ݆ԃ����ÿ��(g��)�΄�(w��)��̎��ƽ�ȵ�λ��Ȼ��oÿ��(g��)�΄�(w��)��ͬ�ĕr(sh��)�gƬ����(d��ng)һ��(g��)�΄�(w��)���\(y��n)�Еr(sh��)�g�����ˣ�����ϵ�y(t��ng)���R���ГQ�o��һ��(g��)��Ҫ��(zh��)�е��΄�(w��)���@�N�����Č�(sh��)�r(sh��)�Բ��ߣ������_����ÿ��(g��)�΄�(w��)������ͬ�Ĉ�(zh��)�Еr(sh��)�g��
�Ұ��@�ɷN�����Y(ji��)�������������O(sh��)����8��(g��)��(y��u)�ȼ�(j��)�M��ÿ��(g��)��(y��u)�ȼ�(j��)�M���涼�Æ���朱��Ѿ�����ͬ��(y��u)�ȼ�(j��)���΄�(w��)�B���������@�ӵ�Ԓ���Ȳ���ϵ�y(t��ng)��(hu��)������߃�(y��u)�ȼ�(j��)���ǽM��Ȼ���ڽM����݆����(zh��)�������΄�(w��)����UCOS II����@�N�����������`���ԣ���?y��n)�UCOS IIֻ�Г�ռʽ�{(di��o)�ȣ��@��UCOS II��Ӳ����������������һ��(g��)�΄�(w��)�Y(ji��)��(g��u)�w�Q�龀�̿��ƉK�����P(gu��n)��ԓ�΄�(w��)�����Р�B(t��i)������һ��
/**
* @�Y(ji��)��(g��u)�w��
* @���Q �� OS_TCB , *pOS_TCB
* @�ɆT �� 1. OS_DataType_ThreadStack *ThreadStackTop
* �����˹��ї����ָ�
* 2. OS_DataType_ThreadStack *ThreadStackBottom
* �����˹��ї�����ָ�
* 3. OS_DataType_ThreadStackSize ThreadStackSize
* �����˹��ї���С
* 4. OS_DataType_ThreadID ThreadID
* ����ID̖(h��o)
* 5. OS_DataType_ThreadStatus ThreadStatus
* �����\(y��n)��B(t��i)
* 6. OS_DataType_PSW PSW
* ӛ䛾��̵ij����B(t��i)�Ĵ���
* 7. struct _OS_TCB *Front
* ָ����һ��(g��)���̿��ƉK��ָ�
* 8. struct _OS_TCB *Next
* ָ����һ�˾��̿��ƉK��ָ�
* 9.struct _OS_TCB *CommWaitNext ;
* ָ��ͨ�ſ��ƉK��ָ�
* 10.struct _OS_TCB *TimeWaitNext ;
* ָ���ӕr(sh��)�ȴ�朱���ָ�
* 11.OS_DataType_PreemptionPriority Priority ;
* �΄�(w��)��(y��u)�ȼ�(j��)
* 12.OS_DataType_TimeDelay TimeDelay ;
* �΄�(w��)�ӕr(sh��)�r(sh��)�g
* @���� �� ���x���̿��ƉK�ijɆT
* @�����r(sh��)�g �� 2011-11-15
* @����ĕr(sh��)�g�� 2011-11-17
*/
typedef struct _OS_TCB{
OS_DataType_ThreadStack *ThreadStackTop ;
OS_DataType_ThreadStack *ThreadStackBottom ;
OS_DataType_ThreadStackSize ThreadStackSize;
OS_DataType_ThreadID ThreadID ;
OS_DataType_ThreadStatus ThreadStatus ;
OS_DataType_PSW PSW ;
struct _OS_TCB *Front ;
struct _OS_TCB *Next ;
#if OS_COMMUNICATION_EN == ON
struct _OS_TCB *CommWaitNext ;
#endif
��
struct _OS_TCB *TimeWaitNext ;
OS_DataType_PreemptionPriority Priority ;
��
OS_DataType_TimeDelay TimeDelay ;
}OS_TCB,*pOS_TCB;
��
���Ȇ���(d��ng)ϵ�y(t��ng)�ĕr(sh��)����Ҫ�Ȅ�(chu��ng)���΄�(w��)���΄�(w��)����(chu��ng)��֮��ſ��Եõ���(zh��)�У�ʹ�����º���(sh��)��
/**
* @���Q�����̄�(chu��ng)������(sh��)
* @ݔ��?y��n)��?sh��)��1.pOS_TCB ThreadControlBlock ���̿��ƉK�Y(ji��)��(g��u)�wָ�
* 2.void (*Thread)(void*) ���̺���(sh��)��ڵ�ַ������һ��(g��)��ָ���ʽ��ݔ��?y��n)��?sh��)���o������(sh��)
* 3.void *Argument ��Ҫ���f�o���̵ą���(sh��)����ָ���ʽ
* @�����r(sh��)�g �� 2011-11-18
* @����ĕr(sh��)�g�� 2011-11-18
*/
void OS_ThreadCreate(pOS_TCB ThreadControlBlock,void (*Thread)(void *),void *Argument)
�P(gu��n)�ڄ�(chu��ng)���΄�(w��)�Ĵ����������ǣ�����̿��ƉK���Ѿ��̿��ƉK朵�����朱��У��O(sh��)���˹��ї�����(x��)��(ji��)�ܶ࣬�Ͳ�һһ٘���ˡ�
��
��(d��ng)ǰ�汾ֻ��(sh��)�F(xi��n)��݆ԃ�{(di��o)�ȣ�߀�]���ϓ�ռ�{(di��o)�ȣ�ʹ������ĺ���(sh��)�Ϳ��Ԇ���(d��ng)����ϵ�y(t��ng)�_ʼ�ྀ���΄�(w��)��
/**
* @���Q �� ��(sh��)�r(sh��)��(n��i)�����l(f��)����(sh��)
* @�汾 �� V 0.0
* @ݔ��?y��n)��?sh��) �� �o
* @ݔ������(sh��) �� �o
* @���� �� ��������(sh��)�����چ���(d��ng)���{(di��o)��ԓ����(sh��)��(hu��)���أ�ֱ���ГQ����߃�(y��u)�ȼ�(j��)�΄�(w��)�_ʼ��(zh��)��
* @�����r(sh��)�g �� 2011-11-15
* @����ĕr(sh��)�g�� 2011-11-15
*/
void OS_KernelStart(void)
{
OS_Status = OS_RUNNING ; //�у�(n��i)�ˠ�B(t��i)�O(sh��)�Þ��\(y��n)�БB(t��i)
��
//ȡ�õ�һ��(g��)��Ҫ�\(y��n)�е��΄�(w��)
OS_CurrentThread = OS_TCB_PriorityGroup[pgm_read_byte(ThreadSearchTab + OS_PreemptionPriority)].OS_TCB_Current;
OS_LastThread = NULL ;
//SPָ�ָ��ԓ�΄�(w��)�ė��
SP = (uint16_t)OS_CurrentThread->ThreadStackTop ;
//ʹ�ó�������
POP_REG();
//�{(di��o)��RET���{(di��o)��֮���_ʼ��(zh��)���΄�(w��)������(hu��)�ٷ��ص��@��
_asm("RET\n\t");
}
��
���ӌ�(sh��)�F(xi��n)�r(sh��)�gƬ�������ö��r(sh��)�����r(sh��)��ÿ�ζ��r(sh��)���a(ch��n)���Д�ĕr(sh��)����D(zhu��n)�Qһ���΄�(w��)���r(sh��)�������Լ��_����һ����f�r(sh��)��ԽС��Ԓ��(hu��)CPU���ܶ��r(sh��)�g���ГQ�΄�(w��)�ϣ�������Ч�ʣ��r(sh��)�����Ԓ��ʹ�r(sh��)�g����׃�֣���(hu��)ʹһЩ����ò������r(sh��)�Ĉ�(zh��)�С����O(sh��)����ÿ10MS�Д�һ�Σ������fÿһ݆��ÿ��(g��)���̶���10MS�Ĉ�(zh��)�Еr(sh��)�g�����w�㷨����٘����
��
��(n��i)���������
����Ҫ���]���ӹ����(n��i)���ˣ���PC���澎�̵ĕr(sh��)�������Ҫ�_��һ��(g��)��(n��i)����g���҂����Ժ������{(di��o)��malloc()��free()����ɣ������چ�Ƭ�C(j��)����s�в�ͨ����?y��n)�Ҫ�?sh��)�F(xi��n)�@�ɂ�(g��)����(sh��)������Ҫ��ɺܶ��㷨֧�֣����ٶȺͿ��g�φ�Ƭ�C(j��)����������
�چ�Ƭ�C(j��)�����������Ҫ�_�ك�(n��i)����g����ֻ���ھ��g�ĕr(sh��)����ȶ��x��׃�����o����(d��ng)�B(t��i)��Ո(q��ng)�������҂������O(sh��)Ӌ(j��)һ��(g��)���εă�(n��i)��������ԁ팍(sh��)�F(xi��n)�@�N��(d��ng)�B(t��i)��Ո(q��ng)��ԭ�������ھ��g�ĕr(sh��)�������g��Ҫһ�K����ă�(n��i)�沢�������o�B(t��i)��Ȼ����@�K���g���o��(n��i)�����ģ�K���{(di��o)�ã���(n��i)�����ģ�Kؓ(f��)؟(z��)�����@�K��(n��i)�棬��(d��ng)���΄�(w��)Ҫ������Ո(q��ng)��(n��i)��ĕr(sh��)�����͏������ó�һ�K���o�΄�(w��)�����΄�(w��)Ҫጷŵĕr(sh��)��Ͱ�ԓ��(n��i)����g���o��(n��i)�����ģ�K�팍(sh��)�F(xi��n)��
�P(gu��n)�ڃ�(n��i)�����Ҳ�кܶ�N���ԣ����@��Ͳ�һһ���f�ˣ�����Դ���a����ʹ����һ�N���ε��S�C(j��)����ķ��������о�����Ո(q��ng)�ĕr(sh��)��͏Į�(d��ng)ǰ��(n��i)��K�Ŀ��ÿ��g���ó�һ�K����Ȼ���ڃ�(n��i)���^����һ��(g��)���õĽY(ji��)��(g��u)�w����ÿ��(g��)��(n��i)��K��朽��������@�ӱ��ڹ�������(d��ng)����ጷŃ�(n��i)��ĕr(sh��)�Ͱу�(n��i)�淵�ص���(n��i)����g�����������g�ă�(n��i)��K�ϲ������ȴ������ٴ��{(di��o)�á�
/**
* @���Q �� ��(n��i)��K��Ո(q��ng)����(sh��)
* @�汾 �� V 0.0
* @ݔ��?y��n)��?sh��) �� 1. OS_DataType_MemorySize MemorySize
��Ҫ��Ո(q��ng)��(n��i)��K�Ĵ�С
* @ݔ������(sh��) �� 1. void *
����Ո(q��ng)�ɹ����t���ؿ�ʹ�Ã�(n��i)��K��ַ����t����NULL
* @���� ��
* @�����r(sh��)�g �� 2011-11-16
* @����ĕr(sh��)�g�� 2011-11-16
*/
#if OS_MEMORY_EN
void *OS_MemoryMalloc(OS_DataType_MemorySize MemorySize)
{
pOS_MCB pmcb = OS_MCB_Head ;
pOS_MCB pmcb2 ;
MemorySize+=OS_MEMORY_BLOCK_SIZE ;
//�M(j��n)���(n��i)�������㷨
while(1)
{
//�z�yԓ��(n��i)��K�Ƿ����
if(pmcb==NULL)
{
return NULL ;
}
//������ڄt�z�yԓ��(n��i)��K��ʹ�à�B(t��i)
else if( (pmcb->Status==OS_MEMORY_STATUS_IDLE) && (pmcb->Size >= MemorySize) )
{
//������Ã�(n��i)��K��С���õ�����Ҫ��Ո(q��ng)�Ĵ�С
//�t��������
if(pmcb->Size == MemorySize)
{
pmcb->Status=OS_MEMORY_STATUS_USING ;
OS_MemoryIdleCount -= MemorySize ;
return (OS_DataType_Memory *)pmcb + OS_MEMORY_SIZE ;
}
//�����Ã�(n��i)��K��С������Ҫ��Ո(q��ng)�Ĵ�С
//�t�M(j��n)�зָ����
else
{
pmcb2=(pOS_MCB)( (OS_DataType_Memory *)pmcb + MemorySize );
pmcb2->Front=pmcb ;
pmcb2->Next=pmcb->Next ;
pmcb2->Status=OS_MEMORY_STATUS_IDLE ;
pmcb2->Size = pmcb->Size - MemorySize ;
pmcb->Status = OS_MEMORY_STATUS_USING ;
pmcb->Size = MemorySize ;
pmcb->Next=pmcb2;
OS_MemoryIdleCount -= MemorySize ;
return (OS_DataType_Memory *)pmcb+OS_MEMORY_BLOCK_SIZE ;
}
}
else
{
pmcb=pmcb->Next;
}
}
}
#endif
��
��(n��i)��ጷź���(sh��)��
/**
* @���Q �� ��(n��i)��Kጷź���(sh��)
* @�汾 �� V 0.0
* @ݔ��?y��n)��?sh��) �� 1. OS_DataType_MemorySize MemorySize
��Ҫ��Ո(q��ng)��(n��i)��K�Ĵ�С
* @ݔ������(sh��) �� 1. void *
����Ո(q��ng)�ɹ����t���ؿ�ʹ�Ã�(n��i)��K��ַ����t����NULL
* @���� ��
* @�����r(sh��)�g �� 2011-11-16
* @����ĕr(sh��)�g�� 2011-11-16
*/
#if OS_MEMORY_EN
void OS_MemoryFree(void *MCB)
{
pOS_MCB pmcb = (pOS_MCB)( (OS_DataType_Memory *)MCB - OS_MEMORY_BLOCK_SIZE );
//����(d��ng)ǰ��(n��i)��K�O(sh��)�Þ���e��B(t��i)
pmcb->Status=OS_MEMORY_STATUS_IDLE ;
OS_MemoryIdleCount += pmcb->Size ;
//���������һ�K��(n��i)��K���t�M(j��n)���Д�
if(pmcb->Front!=NULL)
{
//�����һ�K��(n��i)��K̎�ڿ��e��B(t��i)���t�M(j��n)�кϲ�����
if(pmcb->Front->Status == OS_MEMORY_STATUS_IDLE)
{
pmcb->Front->Size += pmcb->Size ;
pmcb->Front->Next = pmcb->Next ;
pmcb=pmcb->Front ;
OS_MemoryIdleCount += pmcb->Size ;
}
}
//���������һ�K��(n��i)��K���t�M(j��n)���Д�
if(pmcb->Next!=NULL)
{
//�����һ�K��(n��i)��K̎�ڿ��e��B(t��i)���t�M(j��n)�кϲ�����
if(pmcb->Next->Status==OS_MEMORY_STATUS_IDLE)
{
pmcb->Size += pmcb->Next->Size ;
pmcb->Next = pmcb->Next->Next ;
OS_MemoryIdleCount += pmcb->Size ;
}
}
}
#endif
��
�@�N��������mȻ��(sh��)�F(xi��n)���Σ�����ȱ�c(di��n)�������a(ch��n)����(n��i)����Ƭ�����S���r(sh��)�g���ƣ����Ã�(n��i)���(hu��)Խ��Խ��Ƭ�������(d��o)����Ҫ��Ո(q��ng)����ă�(n��i)��K���]�k��������
��
/********************************************************************************/
���ˣ�һ��(g��)���εĆ�Ƭ�C(j��)ʹ�õIJ���ϵ�y(t��ng)ģ�;�������ˣ���(y��ng)����AVR��Ƭ�C(j��)�У������M(j��n)��yԇ�A�Σ�
��?y��n)�߀�]����ɾ���ͨ��ģ�K߀��ռʽ�㷨������Ŀǰֻ�܈�(zh��)��݆ԃ���΄�(w��)�������Ҍ���һ��(g��)�yԇ�����DŽ�(chu��ng)������(g��)��ˮ������ ���Dz����X�Ì���(g��)����ϵ�y(t��ng)���Á�����ˮ��̫���M(f��i)�ˣ�������������ͬ�r(sh��)�W����PROTEUS�з���鿴
���Dz����X�Ì���(g��)����ϵ�y(t��ng)���Á�����ˮ��̫���M(f��i)�ˣ�������������ͬ�r(sh��)�W����PROTEUS�з���鿴
���Dz����X�Ì���(g��)����ϵ�y(t��ng)���Á�����ˮ��̫���M(f��i)�ˣ�������������ͬ�r(sh��)�W����PROTEUS�з���鿴��AVR STUDIO5�_�l(f��)�h(hu��n)���о��������a���£�
#include "includes.h"
#include "OS_core.h"
��
#define STACK_SIZE 80 //���xÿ��(g��)�΄�(w��)���˹��ї���С
��
//���x����(g��)�΄�(w��)���Ե��˹��ї�
uint8_t Test1Stack[STACK_SIZE];
uint8_t Test2Stack[STACK_SIZE];
uint8_t Test3Stack[STACK_SIZE];
��
//���x����(g��)�΄�(w��)���Եľ��̿��ƉK
OS_TCB Task1;
OS_TCB Task2;
OS_TCB Task3;
��
//����1PB���W�q
void Test1(void *p)
{
uint8_t i;
DDRB=0XFF;
PORTB=0xff;
SREG|=0X80;
while(1)
{
for(i=0;i<8;i++) PORTB=1<<i;
}
}
��
//����2PC���W�q
void Test2(void *p)
{
uint8_t i;
DDRC=0xff;
PORTC=0XFF;
SREG|=0X80 ;
while(1)
{
for(i=0;i<8;i++) PORTC=1<<i;
}
}
��
//����3PD���W�q
void Test3(void *p)
{
uint8_t i;
DDRD=0XFF;
PORTD=0xff;
SREG|=0X80;
while(1)
{
for(i=0;i<8;i++) PORTD=1<<i;
}
}
��
//MAIN����(sh��)
int main(void)
{
uint8_t i = 0x77;
//��ʼ������ϵ�y(t��ng)
OS_Init();
��
//��ʼ�����̿��ƉK����(chu��ng)���΄�(w��)
OS_ThreadInit(&Task1,Test1Stack,STACK_SIZE,5,0);
OS_ThreadCreate(&Task1,Test1,&i);
OS_ThreadInit(&Task3,Test3Stack,STACK_SIZE,5,0);
OS_ThreadCreate(&Task3,Test3,&i);
OS_ThreadInit(&Task2,Test2Stack,STACK_SIZE,5,0);
OS_ThreadCreate(&Task2,Test2,&i);
//��ʼ�����r(sh��)��
OS_TimerInit();
��
//����(d��ng)��(n��i)��
OS_KernelStart();
��
//������Ԓ�������h(yu��n)����(hu��)��(zh��)�е��@�����
while(1);
}
��
��
OK���_ʼ�{(di��o)ԇ�������_PROTEUS�B����LOAD����Ȼ���\(y��n)�С�������
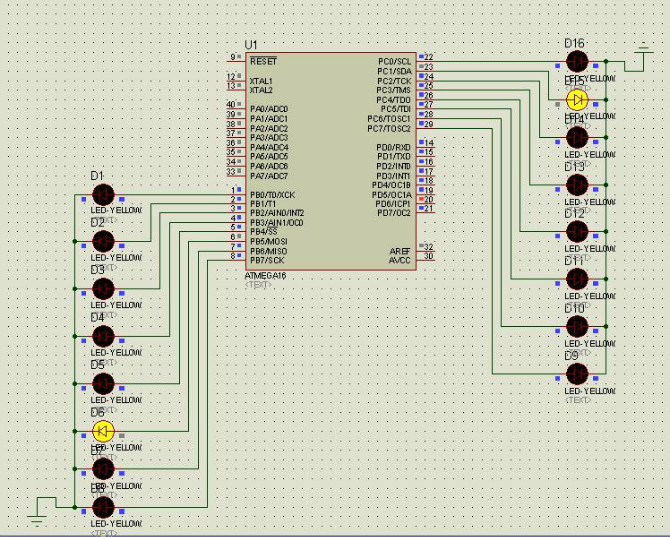
�ɹ�ͬ�r(sh��)�\(y��n)������(g��)��ˮ������̫���ˣ��������@��(g��)��(n��i)�˵�֧������Ϳ��Ԅ�(chu��ng)����đ�(y��ng)�ó����ˣ�ʹ�Ã�(n��i)���ṩ�ľ��̄�(chu��ng)������(sh��)����Ԅ�(chu��ng)��N����(g��)���̣���(d��ng)Ȼ�ˣ�����ڃ�(n��i)��ɽ��ܵķ�����(n��i)�����Ã�(n��i)����亯��(sh��)����Ԅ�(d��ng)�B(t��i)��Ո(q��ng)��ጷŃ�(n��i)���ˡ���Ҳ���Þ�DELAY()�@�N���M(f��i)CPUЧ�ʵ����������ܾ��ˡ��������f�����д��a���_Դ ���뿴��ͬ�W(xu��)�l(f��)�]������EMAIL: wfm2012@126.com ��Ҫ
���뿴��ͬ�W(xu��)�l(f��)�]������EMAIL: wfm2012@126.com ��Ҫ
���뿴��ͬ�W(xu��)�l(f��)�]������EMAIL: wfm2012@126.com ��Ҫ�´��п�����һЩ��(y��ng)�÷���������