cczjw 發表于 2021-11-28 13:45 這都半個月了,還在糾結這個"漢字"? 有這時間,我早就自己寫好一個屬于自己的OLED代碼了,自己去寫代碼,更能加深理解,也能從別人的代碼中得到更好的經驗 |
xhaity 發表于 2021-11-20 11:15 哦,我試試呢。謝謝! |
cczjw 發表于 2021-11-14 23:08 我試了一下,uchar改為uint是可以的啊 struct hzk { unsigned int hzk1; unsigned char hzk4[4]; }; struct hzk const hzkk[] = {"時" ,1,2,3,4,"好",5,6,7,8}; |
cczjw 發表于 2021-11-15 17:12 所以說,既然無所謂翻譯成什么, 那么: #define "時" 0x4712 或者 #define "時" 0x47,0x12 讓編譯過去,不好么? |
Y_G_G 發表于 2021-11-14 14:26 我再試試其它編譯器看是否編譯器的問題。 |
本帖最后由 cczjw 于 2021-11-14 23:26 編輯 xhaity 發表于 2021-11-14 14:04 我將 struct hzk{uchar hzk_2[2],........}; 的 uchar 改為 uint 也不行。 |
xhaity 發表于 2021-11-14 14:04 環境:proteus V8.9 , XC8 V1.31 謝謝! |
188610329 發表于 2021-11-14 22:31 大概明白你的意思。主要是這是別人做的例程,應該是在他的系統中能夠通過。關鍵是這種寫漢字的方法非常方便,一句 “OLED_ShowCHinese(12*8,0,"時",1); ”,把你要寫的漢字放進去就行了它自己去查找不用我再去查編碼。因此 XC8 能夠支持更好,若不能,能夠找到能支持的編譯器也行。謝謝! |
cczjw 發表于 2021-11-14 17:03 不知道該怎么跟你講…… 這么說吧,如果,你把 時 換成 '0' 的話,編譯應該是能通過的。 他會把它翻譯成 0x30,做為這個數組的一部分。 那么,如果,他支持漢字,比如內建了 GB2312 字庫, 那么,編譯的時候,就會把 “時” 翻譯成 0x4712 作為這個數組的一部分,而實際上,一般不會這么做,理由很復雜,三兩句說不清,主要原因就是字庫太多,不管怎么翻都可能會出現錯誤。編譯的時候按GB2312 編譯了, 調用的時候用的 UTF8 去找,同樣一個 “時” 數組里面確死活找不到。 嚴歸正傳,即便支持GB2312 把 “時” 翻譯成 0x4712 實際上最后存在 數組當中的, 還是 0x4712, 所以,你對這個 “時” 能不能通過編譯,為什么那么執著呢? 而且,會有另一個問題, “時” = 0x4712 是一個16位數據,你數組是 8 位的, 這么混合放入數組, 又會出現新的錯誤。 除非,你把后面那些 全都兩兩結合,變成16位數據,數組改成16位的。那么,通過概率還能大點。反正,換了我,寧可用‘S’ 'H' 來索引 也不愿用 “時” 來索引,即便編譯器支持。 因為不知道會幫我編譯成什么。 |
xhaity 發表于 2021-11-14 14:05 我試了,改為 uint 也不行。 |
188610329 發表于 2021-11-14 14:01 如果真是這樣當然要么不用它要么適應它,問題是我現在需確定XC8是否肯定在這種索引操作中不能用 漢字 作索引?還是我語句語法沒用對? |
cczjw 發表于 2021-11-14 13:25 看一下數據手冊,有沒有其它辦法,沒有的話,就只能輸入代碼了 GB2312是漢字字庫,說白了就是中國 芯片廠商重視中國市場,就搞個兼容,不重視,你愛咋咋的,PIC也就這幾年開始重視中國市場,很多芯片都開始有中文的PDF,當初的PIC16F877A這個經典型號可是沒有中文PDF的...... |
| 漢字編碼占用兩個字節,定義為uint |
| 你用的是什么開發平臺呢,是不是MICROCHIP 的MPLAB X IDE, MPLAB X IDE 菜單tool->option->Embedded->Generic settings->Default Charset 選擇 GB2312 應該可以解決這個問題;還有struct hzk{uchar hzk_2[2],........};修改為struct hzk{uint kzk_1,......}; |
cczjw 發表于 2021-11-14 13:25 1) 你遷就編譯器, 他說不許,你就不用。(就像前面說的直接用16進制,然后define唄) 2) 編譯器遷就你,他不許,你就換別的編譯器,直到這個編譯器端正態度,給你用為止,你再考慮用回這個編譯器。 講道底, 商業角度講,這叫買方市場,還是賣方市場。 情感角度,這叫男追女,還是女追男。 要么有一方讓步,要么一拍兩散,沒必要強擰,瓜不甜。 |
188610329 發表于 2021-11-14 13:22 那,這個問題該怎樣解決呢? |
|
一般,嚴謹的編譯器是不會允許使用漢字的,畢竟沒有表頭指定的話,同樣一個漢字GB2312,UTF8, GB18003, 都是不一樣的內碼,編譯器壓根不知道應該按哪個字典來給你譯, 編譯器表示,這個鍋,不背。 |
188610329 發表于 2021-11-13 13:14 你說的這樣確實能夠應急,但我想找到根本原因,便于以后正常使用。  |
|
如果,把這個漢字換成兩個獨立的16進制就不報錯的話……, 你可以嘗試按地板的說法,換成0x42,0x79, 然后,define 一下“時” 為 0x4279 ? |
|
有可能這種寫法只能在51的環境下運行,如果換了單片機,你可能試一下GB2312碼來代替, 比如"時"是:0x42,0x17 (4217)是"時"的代碼 不管是SH1106還是SSD1306,網上都有資料,不要去直接復制別人的代碼,用個兩三天的時間,自己就可以寫了 |
|
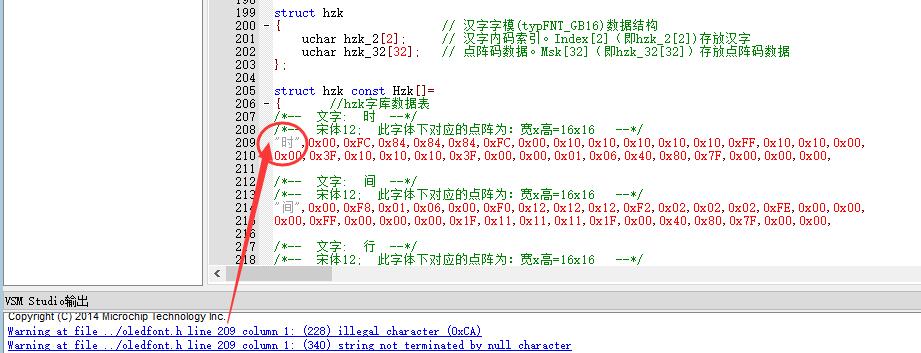
把這個 “時”以及后面的逗號一起刪掉就好了吧…… 你字庫是 16x16 看你一個字 剛好32個字節, 所以,這個“時” 是不應該出現在字庫里才對的。 |