基于Matlab的車牌識別
摘要:車牌識別技術是智能交通系統的重要組成部分,在近年來得到了很大的發展。本文從預處理、邊緣檢測、車牌定位、字符分割、字符識別五個方面,具體介紹了車牌自動識別的原理。并用MATLAB軟件編程來實現每一個部分,最后識別出汽車車牌。
一、設計原理 車輛車牌識別系統的基本工作原理為:將攝像頭拍攝到的包含車輛車牌的圖像通過視頻卡輸入到計算機中進行預處理,再由檢索模塊對車牌進行搜索、檢測、定位,并分割出包含車牌字符的矩形區域,然后對車牌字符進行二值化并將其分割為單個字符,然后輸入JPEG或BMP格式的數字,輸出則為車牌號碼的數字。車牌自動識別是一項利用車輛的動態視頻或靜態圖像進行車牌號碼、車牌顏色自動識別的模式識別技術。其硬件基礎一般包括觸發設備、攝像設備、照明設備、圖像采集設備、識別車牌號碼的處理機等,其軟件核心包括車牌定位算法、車牌字符分割算法和光學字符識別算法等。某些車牌識別系統還具有通過視頻圖像判斷車輛駛入視野的功能稱之為視頻車輛檢測。一個完整的車牌識別系統應包括車輛檢測、圖像采集、車牌識別等幾部分。當車輛檢測部分檢測到車輛到達時觸發圖像采集單元,采集當前的視頻圖像。車牌識別單元對圖像進行處理,定位出車牌位置,再將車牌中的字符分割出來進行識別,然后組成車牌號碼輸出。 二、設計步驟 總體步驟為: 車輛→圖像采集→圖像預處理→車牌定位 →字符分割→字符定位→輸出結果 基本的步驟: a.車牌定位,定位圖片中的車牌位置; b.車牌字符分割,把車牌中的字符分割出來; c.車牌字符識別,把分割好的字符進行識別,最終組成車牌號碼。 車牌識別過程中,車牌顏色的識別依據算法不同,可能在上述不同步驟實現,通常與車牌識別互相配合、互相驗證。 (1)車牌定位: 自然環境下,汽車圖像背景復雜、光照不均勻,如何在自然背景中準確地確定車牌區域是整個識別過程的關鍵。首先對采集到的視頻圖像進行大范圍相關搜索,找到符合汽車車牌特征的若干區域作為候選區,然后對這些侯選區域做進一步分析、評判,最后選定一個最佳的區域作為車牌區域,并將其從圖象中分割出來。      流程圖: 流程圖:
  (2)車牌字符分割 : 完成車牌區域的定位后,再將車牌區域分割成單個字符,然后進行識別。字符分割一般采用垂直投影法。由于字符在垂直方向上的投影必然在字符間或字符內的間隙處取得局部最小值的附近,并且這個位置應滿足車牌的字符書寫格式、字符、尺寸限制和一些其他條件。利用垂直投影法對復雜環境下的汽車圖像中的字符分割有較好的效果。 流程圖:    
  (3)車牌字符識別 :     字符識別方法目前主要有基于模板匹配算法和基于人工神經網絡算法。基于模板匹配算法首先將分割后的字符二值化,并將其尺寸大小縮放為字符數據庫中模板的大小,然后與所有的模板進行匹配,最后選最佳匹配作為結果。基于人工神經元網絡的算法有兩種:一種是先對待識別字符進行特征提取,然后用所獲得特征來訓練神經網絡分配器;另一種方法是直接把待處理圖像輸入網絡,由網絡自動實現特征提取直至識別出結果。實際應用中,車牌識別系統的識別率與車牌質量和拍攝質量密切相關。車牌質量會受到各種因素的影響,如生銹、污損、油漆剝落、字體褪色、車牌被遮擋、車牌傾斜、高亮反光、多車牌、假車牌等等;實際拍攝過程也會受到環境亮度、拍攝亮度、車輛速度等等因素的影響。這些影響因素不同程度上降低了車牌識別的識別率,也正是車牌識別系統的困難和挑戰所在。為了提高識別率,除了不斷的完善識別算法,還應該想辦法克服各種光照條件,使采集到的圖像最利于識別。 字符識別方法目前主要有基于模板匹配算法和基于人工神經網絡算法。基于模板匹配算法首先將分割后的字符二值化,并將其尺寸大小縮放為字符數據庫中模板的大小,然后與所有的模板進行匹配,最后選最佳匹配作為結果。基于人工神經元網絡的算法有兩種:一種是先對待識別字符進行特征提取,然后用所獲得特征來訓練神經網絡分配器;另一種方法是直接把待處理圖像輸入網絡,由網絡自動實現特征提取直至識別出結果。實際應用中,車牌識別系統的識別率與車牌質量和拍攝質量密切相關。車牌質量會受到各種因素的影響,如生銹、污損、油漆剝落、字體褪色、車牌被遮擋、車牌傾斜、高亮反光、多車牌、假車牌等等;實際拍攝過程也會受到環境亮度、拍攝亮度、車輛速度等等因素的影響。這些影響因素不同程度上降低了車牌識別的識別率,也正是車牌識別系統的困難和挑戰所在。為了提高識別率,除了不斷的完善識別算法,還應該想辦法克服各種光照條件,使采集到的圖像最利于識別。
    流程圖: 流程圖:
三 各模塊的實現:3.1輸入待處理的原始圖像:clear ; close all; %Step1 獲取圖像 裝入待處理彩色圖像并顯示原始圖像Scolor = imread('3.jpg');%imread函數讀取圖像文件 
圖3.1原始圖像
3.2圖像的灰度化:彩色圖像包含著大量的顏色信息,不但在存儲上開銷很大,而且在處理上也會降低系統的執行速度,因此在對圖像進行識別等處理中經常將彩色圖像轉變為灰度圖像,以加快處理速度。由彩色轉換為灰度的過程叫做灰度化處理。選擇的標準是經過灰度變換后,像素的動態范圍增加,圖像的對比度擴展,使圖像變得更加清晰、細膩、容易識別。 %將彩色圖像轉換為黑白并顯示 Sgray = rgb2gray(Scolor);%rgb2gray轉換成灰度圖 figure,imshow(Sgray),title('原始黑白圖像'); 
圖3.2原始黑白圖像
3.3對原始圖像進行開操作得到圖像背景圖像: s=strel('disk',13);%strei函數 Bgray=imopen(Sgray,s);%打開sgray s圖像 figure,imshow(Bgray);title('背景圖像');%輸出背景圖像 
圖3.3背景圖像
3.4灰度圖像與背景圖像作減法,對圖像進行增強處理: Egray=imsubtract(Sgray,Bgray);%兩幅圖相減 figure,imshow(Egray);title('增強黑白圖像');%輸出黑白圖像 
圖3.4黑白圖像
3.5取得最佳閾值,將圖像二值化: 二值圖像是指整幅圖像畫面內僅黑、白二值的圖像。在實際的車牌處理系統中,進行圖像二值變換的關鍵是要確定合適的閥值,使得字符與背景能夠分割開來,二值變換的結果圖像必須要具備良好的保形性,不丟掉有用的形狀信息,不會產生額外的空缺等等。車牌識別系統要求處理的速度高、成本低、信息量大,采用二值圖像進行處理,能大大地提高處理效率。閾值處理的操作過程是先由用戶指定或通過算法生成一個閾值,如果圖像中某中像素的灰度值小于該閾值,則將該像素的灰度值設置為0或255,否則灰度值設置為255或0。 fmax1=double(max(max(Egray)));%egray的最大值并輸出雙精度型 fmin1=double(min(min(Egray)));%egray的最小值并輸出雙精度型 level=(fmax1-(fmax1-fmin1)/3)/255;%獲得最佳閾值 bw22=im2bw(Egray,level);%轉換圖像為二進制圖像 bw2=double(bw22); figure,imshow(bw2);title('圖像二值化');%得到二值圖像 
圖3.5二值圖像
3.6邊緣檢測: 兩個具有不同灰度值的相鄰區域之間總存在邊緣,邊緣就是灰度值不連續的結果,是圖像分割、紋理特征提取和形狀特征提取等圖像分析的基礎。為了對有意義的邊緣點進行分類,與這個點相聯系的灰度級必須比在這一點的背景上變換更有效,我們通過門限方法來決定一個值是否有效。所以,如果一個點的二維一階導數比指定的門限大,我們就定義圖像中的次點是一個邊緣點,一組這樣的依據事先定好的連接準則相連的邊緣點就定義為一條邊緣。經過一階的導數的邊緣檢測,所求的一階導數高于某個閾值,則確定該點為邊緣點,這樣會導致檢測的邊緣點太多。可以通過求梯度局部最大值對應的點,并認定為邊緣點,去除非局部最大值,可以檢測出精確的邊緣。一階導數的局部最大值對應二階導數的零交叉點,這樣通過找圖像強度的二階導數的零交叉點就能找到精確邊緣點。 grd=edge(bw2,'canny')%用canny算子識別強度圖像中的邊界 figure,imshow(grd);title('圖像邊緣提取');%輸出圖像邊緣 
圖3.6像邊緣提取
3.7對得到圖像作開操作進行濾波: 數學形態非線性濾波,可以用于抑制噪聲,進行特征提取、邊緣檢測、圖像分割等圖像處理問題。腐蝕是一種消除邊界點的過程,結果是使目標縮小,孔洞增大,因而可有效的消除孤立噪聲點;膨脹是將與目標物體接觸的所有背景點合并到物體中的過程,結果是使目標增大,孔洞縮小,可填補目標物體中的空洞,形成連通域。先腐蝕后膨脹的過程稱為開運算,它具有消除細小物體,并在纖細處分離物體和平滑較大物體邊界的作用;先膨脹后腐蝕的過程稱為閉運算,具有填充物體內細小空洞,連接鄰近物體和平滑邊界的作用。對圖像做了開運算和閉運算,閉運算可以使圖像的輪廓線更為光滑,它通常用來消掉狹窄的間斷和長細的鴻溝,消除小的孔洞,并彌補輪廓線中的斷裂。 bg1=imclose(grd,strel('rectangle',[5,19]));%取矩形框的閉運算 figure,imshow(bg1);title('圖像閉運算[5,19]');%輸出閉運算的圖像 bg3=imopen(bg1,strel('rectangle',[5,19]));%取矩形框的開運算 figure,imshow(bg3);title('圖像開運算[5,19]');%輸出開運算的圖像 bg2=imopen(bg3,strel('rectangle',[19,1]));%取矩形框的開運算 figure,imshow(bg2);title('圖像開運算[19,1]');%輸出開運算的圖像  
圖3.7.1閉運算的圖像 圖3.7.2開運算的圖像 
圖3.7.3開運算的圖像
3.8對二值圖像進行區域提取,并計算區域特征參數。進行區域特征參數比較,提取車牌區域: a.對圖像每個區域進行標記,然后計算每個區域的圖像特征參數:區域中心位置、最小包含矩形、面積。 [L,num] = bwlabel(bg2,8);%標注二進制圖像中已連接的部分 Feastats = imfeature(L,'basic');%計算圖像區域的特征尺寸 Area=[Feastats.Area];%區域面積 BoundingBox=[Feastats.BoundingBox];%[x y width height]車牌的框架大小 RGB = label2rgb(L, 'spring', 'k', 'shuffle'); %標志圖像向RGB圖像轉換 figure,imshow(RGB);title('圖像彩色標記');%輸出框架的彩色圖像 
圖3.8.1彩色圖像 b. 計算出包含所標記的區域的最小寬和高,并根據先驗知識,比較誰的寬高比更接近實際車牌寬高比,將更接近的提取并顯示出來。 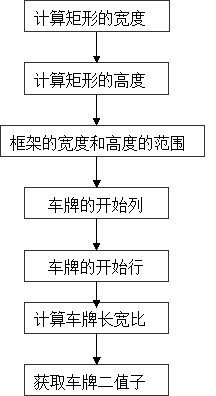 
程序流程圖 圖3.8.2灰度子圖和二值子圖
3.9對水平投影進行峰谷分析: 對水平投影進行峰谷分析,計算出車牌上邊框、車牌字符投影、車牌下邊框的波形峰上升點、峰下降點、峰寬、谷寬、峰間距離、峰中心位置參數。 histcol1=sum(sbw1); %計算垂直投影 histrow=sum(sbw1'); %計算水平投影 figure,subplot(2,1,1),bar(histcol1);title('垂直投影(含邊框)');%輸出垂直投影 subplot(2,1,2),bar(histrow); title('水平投影(含邊框)');%輸出水平投影 
圖3.9.1垂直投影和水平投影 figure,subplot(2,1,1),bar(histrow); title('水平投影(含邊框)');%輸出水平投影 subplot(2,1,2),imshow(sbw1);title('車牌二值子圖');%輸出二值圖 對水平投影進行峰谷分析: 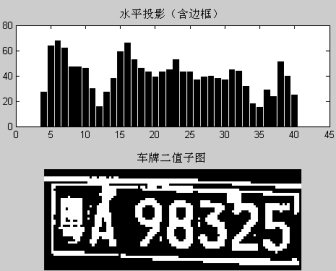 
圖3.9.2水平投影和二值圖 程序流程圖
3.10計算車牌旋轉角度: a.車牌傾斜的原因導致投影效果峰股谷不明顯,在這里需要做車牌矯正處理。這里采取的線性擬合的方法,計算出車牌上邊或下邊圖像值為1的點擬合直線與水平X軸的夾角。 
程序流程圖 (2)線性擬合,計算與x夾角 fresult = fit(xdata',ydata','poly1'); %poly1表示一介擬合 Y = p1*x+p2 p1=fresult.p1; angle=atan(fresult.p1)*180/pi; %弧度換為度,360/2pi, pi=3.14 (3)旋轉車牌圖象 subcol = imrotate(subcol1,angle,'bilinear','crop'); %旋轉車牌圖象 sbw = imrotate(sbw1,angle,'bilinear','crop');%旋轉圖像 figure,subplot(2,1,1),imshow(subcol);title('車牌灰度子圖');%輸出車牌旋轉后的灰度圖像標題顯示車牌灰度子圖 subplot(2,1,2),imshow(sbw);title('');%輸出車牌旋轉后的灰度圖像 title(['車牌旋轉角: ',num2str(angle),'度'] ,'Color','r');%顯示車牌的旋轉角度 
圖3.10.1旋轉后的灰度圖像和旋轉角度 b.旋轉車牌后重新計算車牌水平投影,去掉車牌水平邊框,獲取字符高度: histcol1=sum(sbw); %計算垂直投影 histrow=sum(sbw'); %計算水平投影 figure,subplot(2,1,1),bar(histcol1);title('垂直投影(旋轉后)'); subplot(2,1,2),bar(histrow); title('水平投影(旋轉后)'); 
圖3.10.2垂直投影(旋轉后)和水平投影(旋轉后) figure,subplot(2,1,1),bar(histrow); title('水平投影(旋轉后)'); subplot(2,1,2),imshow(sbw);title('車牌二值子圖(旋轉后)'); 
圖3.10.3水平投影(旋轉后)和車牌二值子圖(旋轉后)
3.11去水平(上下)邊框,獲取字符高度: a.通過以上水平投影、垂直投影分析計算,獲得了車牌字符高度、字符頂行與尾行、字符寬度、每個字符的中心位置,為提取分割字符具備了條件。 maxhight=max(markrow2); findc=find(markrow2==maxhight); rowtop=markrow(findc); rowbot=markrow(findc+1)-markrow1(findc+1); sbw2=sbw(rowtop:rowbot,:); %子圖為(rowbot-rowtop+1)行 maxhight=rowbot-rowtop+1; %字符高度(rowbot-rowtop+1) b.計算車牌垂直投影,去掉車牌垂直邊框,獲取車牌及字符平均寬度 histcol=sum(sbw2); %計算垂直投影 figure,subplot(2,1,1),bar(histcol);title('垂直投影(去水平邊框后)');%輸出車牌的垂直投影圖像 subplot(2,1,2),imshow(sbw2); %輸出垂直投影圖像 title(['車牌字符高度: ',int2str(maxhight)],'Color','r');%輸出車牌字符高度 %對垂直投影進行峰谷分析 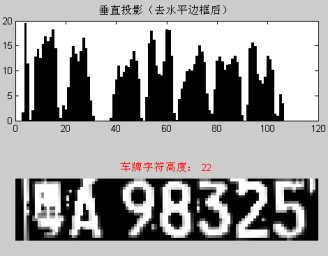 
圖3.11垂直投影圖像和車牌字符高度 程序流程圖 c.計算車牌上每個字符中心位置,計算最大字符寬度maxwidth l=0; for k=1:n1 markcol3(k)=markcol(k+1)-markcol1(k+1);%字符下降點 markcol4(k)=markcol3(k)-markcol(k); %字符寬度(上升點至下降點) markcol5(k)=markcol3(k)-double(uint16(markcol4(k)/2));%字符中心位置 end markcol6=diff(markcol5); %字符中心距離(字符中心點至下一個字符中心點) maxs=max(markcol6); %查找最大值,即為第二字符與第三字符中心距離 findmax=find(markcol6==maxs); markcol6(findmax)=0; maxwidth=max(markcol6);%查找最大值,即為最大字符寬度 d.提取分割字符,并變換為22行*14列標準子圖 l=1; [m2,n2]=size(subcol); figure; for k=findmax-1:findmax+5 cleft=markcol5(k)-maxwidth/2; cright=markcol5(k)+maxwidth/2-2; if cleft<1 cleft=1; cright=maxwidth; end if cright>n2 cright=n2; cleft=n2-maxwidth; end SegGray=sbw(rowtop:rowbot,cleft:cright); SegBw1=sbw(rowtop:rowbot,cleft:cright); SegBw2 = imresize(SegBw1,[22 14]); %變換為22行*14列標準子圖 subplot(2,n1,l),imshow(SegGray); if l==7 title(['車牌字符寬度: ',int2str(maxwidth)],'Color','r'); end subplot(2,n1,n1+l),imshow(SegBw2); fname=strcat('F:\MATLAB\work\sam\image',int2str(k),'.jpg');%保存子圖備選入樣本庫,并建立樣本庫 imwrite(SegBw2,fname,'jpg') l=l+1; end
3.12將計算計算獲取的字符圖像與樣本庫進行匹配,自動識別出字符代碼: 進行車牌識別前需要使用樣本對神經網絡進行訓練,然后使用訓練好的網絡對車牌進行識別。其具體流程為:使用漢字、字母、字母數字、數字四個樣本分別對四個子網絡進行訓練,得到相應的節點數和權值。對已經定位好的車牌進行圖像預處理,逐個的特征提取,然后從相應的文件中讀取相應的節點數和權值,把車牌字符分別送入相應的網絡進行識別,輸出識別結果。  
程序流程圖 圖3.12識別的車牌號碼
四、設計結果及分析 原始圖像: 預處理后:  
車牌定位和提取: 字符的分割和識別:  
可以看出對于這個車牌,可以準確的識別。
原始圖像: 預處理:  
車牌的定位和提取: 字符的分割和識別:  
從上面結果可以看出,這張車牌的識別失敗了,將G誤識別為B了,K誤識為A,0識別為8,這在識別中是非常容易出錯的地方,因此需要在其他方面做些彌補,最后達到識別效果。 在車牌識別的過程中數字庫的建立很重要,只有數字庫的準確才能保證檢測出來的數據正確。切割出來的數據要與數據庫的數據作比較,所以數據庫的數據尤為重要。
五、總結: 實驗對車牌識別系統的軟件部分進行了研究,分別從圖像預處理、車牌定位、字符分割以及字符識別等方面進行了系統的分析。整理和總結了國內外在車牌定位、分割、字符識別方面的研究成果和發展方向,系統介紹了我國車牌的固有特征,以及車牌識別的特點。在車牌定位我們采用基于灰度跳變的定位方法,采用先對圖像進行預處理,再進行二值化操作的方法。實驗表明本方法既保留了車牌區域的信息,又減少了噪聲的干擾,從而簡化了二值化處理過程,提高了后續處理的速度。基于彩色分量的定位方法,運用基于藍色象素點統計特性的方法對車牌是藍色的車牌進行定位,實驗表明,用該方法實現的車牌定位準確率較高。
完整的Word格式文檔51黑下載地址:
 基于Matlab的車牌識別(完整版).doc
(1.37 MB, 下載次數: 193)
基于Matlab的車牌識別(完整版).doc
(1.37 MB, 下載次數: 193)
2018-10-16 12:23 上傳
點擊文件名下載附件
| 
 [復制鏈接]
[復制鏈接]





